Урок 25: April Tag - этап 1: обнаружение
- Сайт AprilTag
- Статья которую мы будем реализовывать - AprilTag: A robust and flexible visual fiducial system, Edwin Olson, 2011
Мы обсудим как решить следующую задачу - пусть мы можем нарисовать (обычно распечатать на листе бумаги или пластика) какие-то специальные картинки (тэги), возможно даже несколько - каждая из этих картинок имеет свой идентификатор (код, по сути просто уникальное число). И теперь мы хотим эти картинки быстро и надежного распознавать на фотографии. В т.ч. хотим понимать какой из тэгов где.
Можно было бы решать это через ключевые точки общего назначения (SIFT и т.п.), но они работают довольно медленно и кроме того оказывается что если разработать специализированный тэг - то он будет гораздо лучше обнаружаться и позволит надежно работать даже в сложных условиях.
Пример как выглядят AprilTag (обратите внимание что справа на тэги наложены расшифрованные идентификаторы - числа которые были декодированы из обнаруженных тэгов):

Два этапа: детекция и декодирование
Our system is composed of two major components: the tag
detector and the coding system. In this section, we describe
the detector whose job is to estimate the position of possible
tags in an image. Loosely speaking, the detector attempts to
find four-sided regions (“quads”) that have a darker interior
than their exterior. The tags themselves have black and white
borders in order to facilitate this (see Fig. 2).
Итак, в статье две ключевые части:
1) Детекция тэга (попытка найти темные четырехугольники - это внешние границы)
2) Система декодирования обнаруженного тэга (в тэге можно хранить числа чтобы различать один тэг от другого)
Сегодня мы обсудим только первый этап - детекции, т.е. обнаружения тэгов.
Не хотим пропустить тэг пусть и ценой обнаружения иллюзий
Note that the quad detector is designed to have a very
low false negative rate, and consequently has a high false
positive rate. We rely on the coding system (described in
the next section) to reduce this false positive rate to useful
levels.
Любопытное решение - детектор планировалось сделать так чтобы он максимально редко выдавал ложно-отрицательный результат
(т.е. редко не обнаруживал тэг, пусть и ценой перегиба в сторону обнаружения тэга там где его нет - т.е. пусть и ценой частого
ложно-положительного результата).
Но раз мы почти всегда видим тег там где он есть, и довольно часто видим тег там где его нет - как с этим работать? Как не страдать от иллюзий? Давайте просто полагаться что на второй ключевой части - системе декодирования - мы поймем что это не тег, а какая-то случайная ерунда, и просто отсечем такие ложно-положительные результаты.
Т.о. с одной стороны мы почти никогда не пропускаем тэги (редки ложно-отрицательные случаи) пусть и ценой частых ложно-положительных случаев,
которые мы устраняем на следующем этапе обработки - на этапе декодирования номера тэга мы планируем понять что это не тэг а какая-то ерунда.
P.S. на тему ложно-негативных и т.п. результатов:
Бывают положительные и отрицательные результаты работы алгоритма:
-
Положительный(не обязательно это хорошо) - нашли тег на картинке (при этом он там может быть на самом деле, или это иллюзия) -
Отрицательный(не обязательно это плохо) - не нашли тег на картинке (при этом его там может не быть на самом деле, или же есть но мы его не заметили)
А с учетом того что на самом деле на картинке - результат работы алгоритма может быть поделен на истинные и ложные (когда ошибся), вот и выходит:
-
Истинно-положительный- когда алгоритм нашел тэг на картинке, и это правильный ответ, нашел действительно тэг а не какую-то ерунду -
Ложно-положительный- когда алгоритм думал что нашел тэг на картинке, но это неправильный ответ, а алгоритм нашел что-то (может быть) похожее на тэг, но не тэг -
Истинно-отрицательный- когда алгоритм решил что на картинке нет тэга, и это правильный ответ -
Ложно-отрицательный- когда алгоритм думает что на картинке нет тэга, но это не так - тэг есть, просто алгоритм его не заметил (т.е. ошибся)
3) Обнаружаем границы-отрезки

..., computes the gradient direction and magnitude at every pixel
(see Fig. 3) and agglomeratively clusters the pixels into
components with similar gradient directions and magnitudes.
Итак в целом обнаружение границ-отрезков задающих четырехугольник тэга находится через нахождение по-пиксельных градиентов и постепенного объединения их в компоненты (кластеризация) на основе похожести направления и силы градиентов.
The clustering algorithm ...: a graph is created in which
each node represents a pixel. Edges are added between
adjacent pixels with an edge weight equal to the pixels’
difference in gradient direction.
1) Итак создается граф: вершина=пиксель, ребра=смежные пиксели, длина ребра=разница в направлении градиентов смежных пикселей
Изначально каждый пиксель в своей компоненте (в своем кластере).
These edges are then sorted and
processed in terms of increasing edge weight: for each edge,
we test whether the connected components that the pixels
belong to should be joined together.
2) Все ребра сортируются и обрабатываются по возрастанию их длины, т.е. сначала обрабатываем пары пикселей с похожими градиентами.
Для очередного ребра мы делаем следующее:
2.1) Смотрим какие пиксели он соединяет, смотрим в каких двух компонентах эти пиксели состоят
2.2) Хотим решить надо ли объединить эти две компоненты связности друг с другом в одну общую компоненту связности (т.е. мы пытаемся понять - эти два набора пикселей - один и тот же связный отрезок, или два разных)
Given a component n,
we denote the range of gradient directions as D(n) and the
range of magnitudes as M(n). Put another way, D(n) and
M(n) are scalar values representing the difference between
the maximum and minimum values of the gradient direction
and magnitude respectively.
2.3) У каждой компоненты связности \(n\) есть множество пикселей которые в нее входят, у каждого пикселя есть свой градиент. Тогда у компоненты есть \(D(n)\)=диапазон направлений (\(D\)=Direction=направление) этих градиентов, \(M(n)\)=диапазон силы, т.е. длины (\(M\)=Magnitude) этих градиентов.
Given two components n and m,
we join them together if both of the conditions below are
satisfied
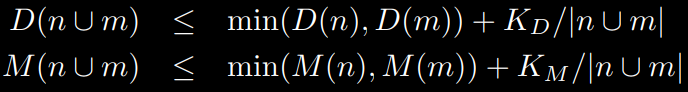
2.4) Итак мы объединяем две компоненты связности если после их объединения диапазон направлений градиентов и диапазон силы градиентов не сильно увеличиться у обеих компонент (поэтому справа минимум).
Не сильно увеличится - задается вторым слагаемым в приведенных выше формулах, и по сути это константа деленная на суммарное число пикселей. \(K_D=100\) (в градусах) и \(K_M=1200\) (в пикселях).
Обратите внимание - зачем нам делать дозволенное увеличение диапазонов все меньше и меньше по мере увеличения компоненты? Что будет в начале? Компоненты из одиночных пикселей - мы их объединяем если градиенты хоть сколько-то не в противоположном направлении (плюс-минус 50 градусов - дозволенная разница). Что будет в конце? Огромные компоненты там где истинные отрезки (с четким пониманием какое направление и сила градиентов, т.е. малые диапазоны), и много мелких компонент в остальных местах.
Благодаря таким формулам-критериям огромные компоненты (по сути отрзеки) не будут объединяться с мелкими компонентами (по сути шум). За исключением случая когда эти мелкие компоненты покрывают продолжение отрезка этих огромных компонент (т.е. случая когда их градиенты похожи на градиенты большой компоненты).
Т.е. чем больше у нас пикселей в компоненте - тем сильнее мы уверены что диапазон градиентов определн правильно, а значит разрешаются только объединения которые очень слабо увеличивают диапазон (отсюда деление на общее число пикселей).
This gradient-based clustering method is sensitive to noise
in the image: even modest amounts of noise will cause local
gradient directions to vary, inhibiting the growth of the components.
The solution to this problem is to low-pass filter the image
... We recommend a value of σ = 0.8.
Обратите внимание что даже малый шум может существенно влиять на направления градиентов, а наш алгоритм к такому чувствителен. Достаточно слегка поблюрить картинку чтобы это побороть.
Once the clustering operation is complete, line segments
are fit to each connected component using a traditional
least-squares procedure, weighting each point by its gradient
magnitude (see Fig. 3). We adjust each line segment so that
the dark side of the line is on its left, and the light side is
on its right. In the next phase of processing, this allows us
to enforce a winding rule around each quad.
2.5) Когда все ребра обработаны и компоненты связности определены - в каждой компоненты связности надо найти “общий отрезок-прямую”. Предлагается это сделать с помощью метода наименьших квадратов, и это стандартный хороший метод, но давайте сделаем это просто и наивно - через RANSAC.
Для удобства в следующем этапе обработки удобно фиксировать направление отрезка так чтобы “слева” от направленного отрезка была черная зона, а справа - белая. Тогда мы знаем что тэги (а они черные) огибаются против часовой стрелки:

4) Обнаружаем четырехугольники

At this point, a set of directed line segments have been
computed for an image. The next task is to find sequences
of line segments that form a 4-sided shape, i.e., a quad. The
challenge is to do this while being as robust as possible to
occlusions and noise in the line segmentations.
Итак, у нас есть компоненты связности задающие отдельно взятые отрезки на нашей картинке. Из них мы хотим собрать четырехугольники которые могли бы оказаться искомыми тэгами.
Our approach is based on a recursive depth-first search
with a depth of four: each level of the search tree adds an
edge to the quad. At depth one, we consider all line segments.
At depths two through four, we consider all of the line
segments that begin “close enough” to where the previous
line segment ended and which obey a counter-clockwise
winding order. Robustness to occlusions and segmentation
errors is handled by adjusting the “close enough” threshold:
by making the threshold large, significant gaps around the
edges can be handled. Our threshold for “close enough” is
twice the length of the line plus five additional pixels. This
is a large threshold which leads to a low false negative rate,
but also results in a high false positive rate.
Предлагается делать перебор который немного напоминает поиск в глубину (DFS) - мы хотим найти четыре отрезка, вложенно перебирая их и отсекая комбинации которые нам не подходят.
Критерий отсечения:
-
Вот мы выбрали первый отрезок - какой отрезок подходит на роль второго (следующего за первым)? Тот у которого начало недалеко от конца первого. Здесь нам очень помогает порядок обхода сделанный ранее, иначе мы бы не знали где у отрезка “начало” а где “конец”
-
Тэги темные, мы их обходим против часовой стрелки, значит у следующего отрезка направление должно заворачивать налево (относительно предыдущего)
-
Вот мы выбрали все четыре отрезка - надо проверить что четвертый отрезок закончился где-то недалеко от начала первого
Чем больше это самое недалеко - тем более чувствителен алгоритм обнаружения - чаще находит тэги, но и чаще находит мусор.
В статье используют удвоенную длину отрезка плюс 5 пикселей.
Обратите внимание что перебирать отрезки чье начало недалеко от конца предыдущего отрезка - можно очень быстро (используя алгоритмические структуры вроде Kd-деревьев), но для упрощения предлагается просто явно пробегать по всем отрезкам с зажатым порогом.
Кроме того вероятно из компонент связности нас интересуют только те у которых достаточно большое число пикселей.