Урок 23: многопоточность (lock, критическая секция)
Однопоточоная модель вычислений
Все это время мы мыслили в модели вычислений когда программа шаг за шагом выполняет одну инструкцию за другой.
Могут быть команды которые меняют порядок выполнения инструкций:
forпозволяет выполнять некоторый набор последовательных команд пока выполняется некоторое правило (предикат),ifпозволяет выполнять набор команд только в некоторых случаях,- вызов функции может выполнить прыжок (в ассемблере для этого используется инструкция
jump) исполнения команд в другое место
выглядит это примерно так - есть набор инструкций, есть указатель на инструкцию выполняемую в данный момент (instruction pointer) и оперативная память которую эти инструкции меняют:
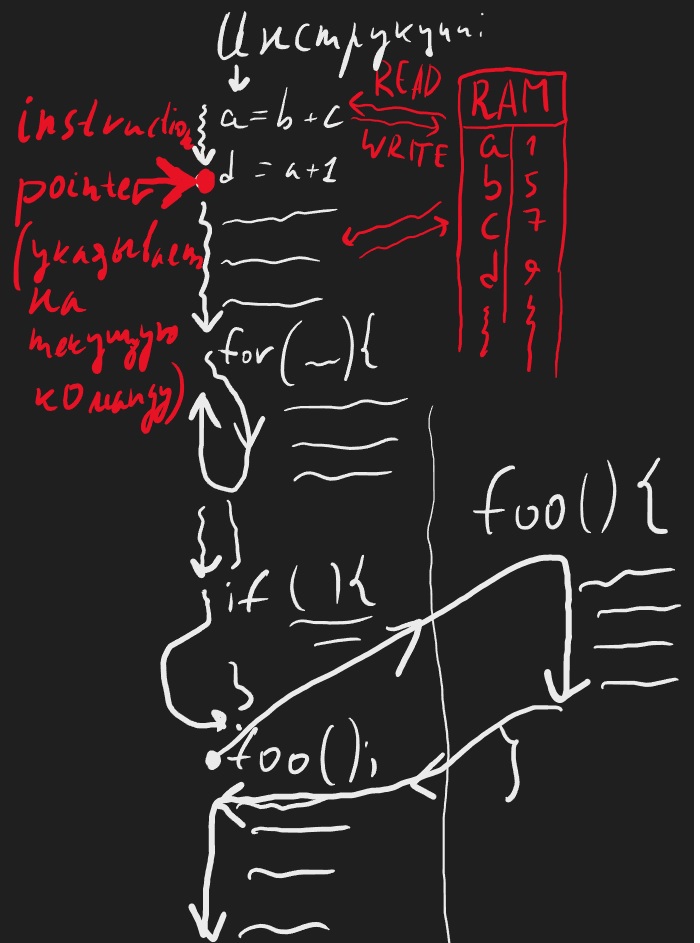
Многопоточная модель вычислений
Но скорость работы программы определяется тем сколько команд в секунду выполняет процессор.
В какой-то мере эта скорость определяется частотой процессора.
Например процессор с частотой 3 GHz может выполнять примитивные команды со скоростью около 3 миллиарда примитивных операций в секунду.
И такая частота работы процессора была достигнута уже около 2004 года, и с тех пор росла несущественно, хотя до 2004 года довольно много лет (условно 10-20 лет) частота процессора росла быстро - примерно в два раза каждые два года. См. так же Закон Мура.
Как же продолжать получать достигать увеличения мощности процессоров? Ведь это необходимо например для серверного рынка.
Давайте скажем что одновременно у нас выполняется много программ, пользователь может одновременно смотреть youtube, слушать музыку, играть в сапера и т.п., все эти программы работают параллельно.
Что если создать в процессоре несколько вычислительных ядер - каждое из которых будет работать как мы привыкли - в модели однопоточного вычисления - независимо от других ядер?
Мы получим ускорение, ведь теперь не придется делить силы одного ядра на все эти программы, мы получили увеличение общей вычислений мощности во столько раз сколько ядер в процессоре.
Но что если мы хотим ускорить работу одной отдельно взятой программы? Что если мы хотим часть задачи считать в одном потоке (на одном ядре), другую часть задачи считать в другом потоке (на другом ядре) и за счет этого получить ускорение? Тогда нам нужно уметь обмениваться данными между этими потоками - например чтобы находить общий ответ в вычисляемой задаче (представьте что мы хотим просуммировать числа массива). Для этого у нас уже есть оперативная память, но возникает одна большая проблема.
Проблема гонки (Race condition)
Пример с Jenga Представьте что у нас есть Вася и Петя. Каждый из них достиг невиданных высот в мастерстве игры в Дженгу:

Каждый из них всегда делал свой ход безукоризненно, всегда грамотно выбирал какую деревяшку можно вытащить, и успешно ее вытаскивал!
Но что если Вася и Петя сделают ход абсолютно синхронно? Что если они выберут две деревяшки с одного и того же уровня, или хуже того - просто одну и ту же деревяжку?
Тогда они помешают друг другу и результат может быть непредсказуем. Было бы лучше им сначала решить кто ходит первый, а кто второй. Тем самым гарантировав что в любой момент с башней взаимодействует не больше одного игрока, а значит никто ему не помешает.
Пример с банком Представим что есть два банкомата и многоликий Коля. Этот многоликий Коля может одновременно быть везде и нигде. Взаимодействовать абсолютно синхронно с любым числом предметов, даже с банкоматами.
При этом банк из-за большого числа клиентов все транзакции из банкоматов выполняет на разных ядрах процессора (их могут быть тысячи).
В таком случае может случиться следующее:
1) У Коли была 1000 рупий на счету
2) Он синхронно с банкомата А снял 100 рупий, и с банкомата Б снял 200 рупий
3) Каждое снятие выполняется на отдельном вычислительном ядре процессора, но то сколько денег на счету Коли хранится в одной и той же переменной счет в оперативной памяти
4) Кроме того каждое снятие это три инструкции процессора:
4.1) считать информацию из оперативной памяти о количестве денег на счете
4.2) проверить достаточно ли денег
4.3) посчитать сколько денег осталось
4.4) сохранить в оперативной памяти новое число на счете
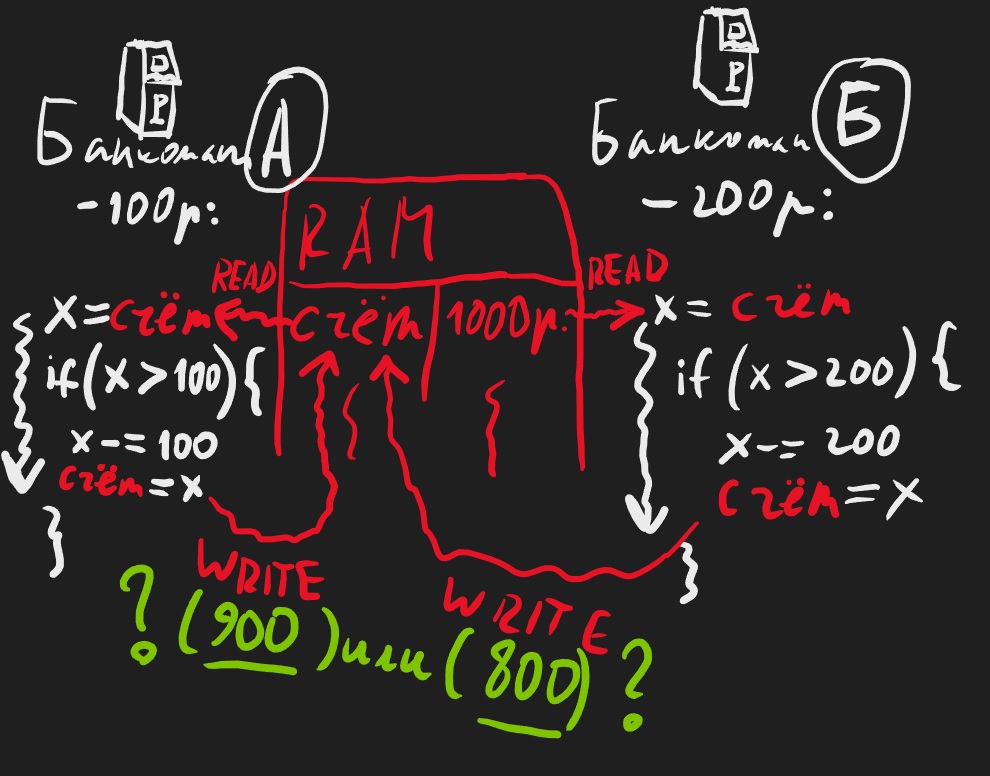
Но в таком случае на счете сохранится то ли 900 рупий, то ли 800 рупий. Банку очень не понравится такая многопоточность!
Подобная ошибка, или даже скорее - подобная ситуация и состояние называется состоянием гонки (Race condition). Ведь два потока буквально соревнуются “кто первый!”, и ирония в том что побеждает скорее тот кто последний - ведь именно его результаты будут сохранены в памяти. При этом обычно результат зависит от воли случая, и в этом коварство гонки - она может приводить к сложно отслеживаемым и трудновоспроизводимым (а значит тяжко отлаживаемым) ошибкам в коде.
Что делать (lock и критическая секция)
Оказывается существует инструмент который позволяет указать что эту часть программы может выполнять только один поток. Например если мы хотим просуммировать все элементы массива - давайте скажем что один поток считает левую половину, а второй считает вторую половину. Но нам нужно будет результаты их работы просуммировать. Тогда давайте добавлять их частичную сумму к переменной с общим ответом. Но делать это нужно обязательно без состояния гонки.
Справиться с этим поможет инструмент lock (в переводе - защелка) и он позволяет сказать что мы делаем какую-то опасную инструкцию (добавление нашей частичной суммы к общему ответу), мы боимся гонки, мы боимся что другой поток тоже будет добавлять частичную сумму и все испортиться.
А значит давайте скажем что в один и тот же момент времени добавлять частичную сумму к результату может только один поток.
Иначе говоря давайте создадим специальную комнату, выполняя команды в которой мы имеем гарантии что никто другой в этой комнате нам не помешает. Что-то вроде уборной - защелка на входе (отсюда название lock) позволяет быть уверенным что нам не помешают. В коде секция с командами которые проводятся с такой гарантией называется критической секцией:
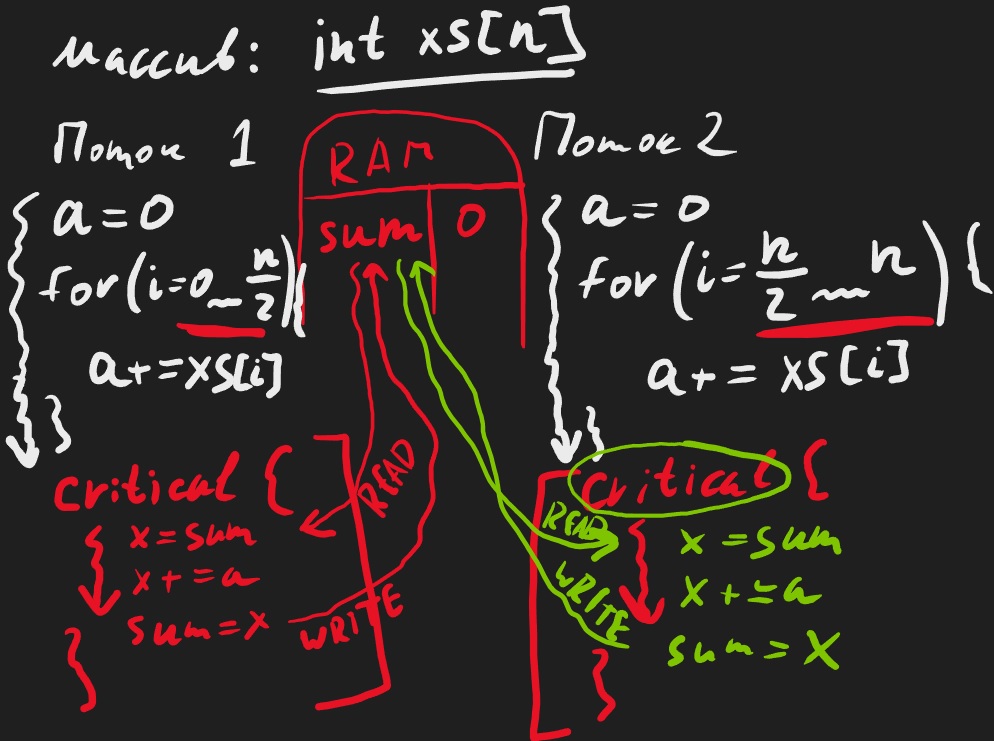
Благодаря тому что суммирование частичных сумм выполняется из критической секции - сначала один из потоков сделает свои дела, т.е. узнает какая была общая сумма (пока что 0), затем посчитает новую сумму (т.е. 0+a) и сохранит ее в оперативной памяти. И лишь затем, дождавшись когда один поток выполнит свою задачу - другой поток постучавшись и увидев что уборная свободна зайдет и сделает свои дела. Т.е. узнает какая общая сумма на данный момент (увидит новую сумму - частичную сумму сохраненную первым потоком), посчитает новую сумму (т.е. добавит свой результат) и сохранит ее в опреативной памяти.