Урок 22: ретуширование фотографии (быстро и качественно, PatchMatch)
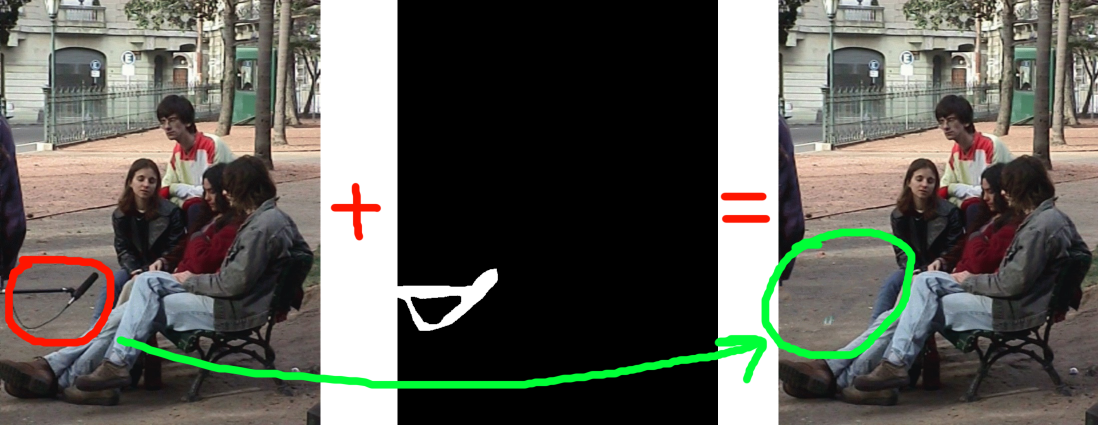
Постановка задачи и базовой идеи:
- Хотим залатать дырку в картинке (дырка задается маской)
- Вместо залатывания монотонным цветом - хотим чтобы выглядело естественно
- Поэтому залатываем дырку беря наиболее подходящие доноры-заплатки из других частей картинки:
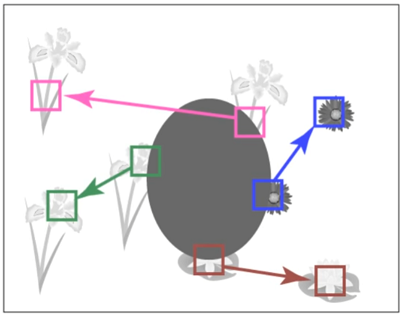
Основные идеи предыдущей попытки:
- Давайте хранить в каждом пикселе стрелочку как на иллюстрации выше - указание откуда берется донор-заплатка
- Научимся замерять качество заплатки через сумму разницы цветов в окрестности патча (например 7х7 пикселей)
- Будем рассматривать новые случайные стрелочки и заменять старые на новые если в таком случае качество растет
Как можно коротко охарактеризовать такую попытку? По своей сути это что-то вроде перебора: чем дольше мы ждем - тем больше вариантов будет рассмотрено, а значит больше шансов найти хороший ответ.
Но как увеличить шансы найти хороший ответ за минимальное число попыток? Т.е. как увеличить качество и при этом ускорить?
Идея 1: заметим что доноры-заплатки согласованы (Propagation=распространение)
Если есть какое-то хорошее сопоставление - то почти наверняка такую же стрелочку стоит провести и для наших соседей. Иначе говоря наши соседи хотят сопоставляться с соседями нашего сопоставления:
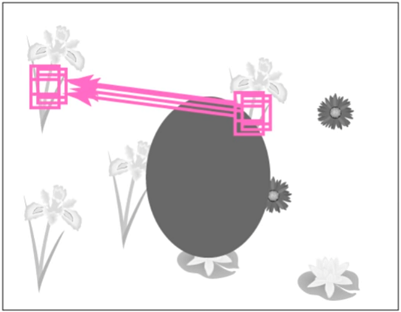
Как это реализовать? Давайте предложим пикселю вместо случайной гипотезы, вместо случайного смещения - смещение которое на данный момент сохранено как лучшее у пикселя слева от нас. Оценим качество такого смещения для нас, по сути - примерим его на себя, если нам подошло, если наше качество выросло - то надо сохранить для себя такое смещение.
А кто еще может вдохновить нас такими идеями? Например сосед сверху, сосед справа и сосед снизу.
Из этого вытекает идея этапа Propagation (в переводе - распространение):
1) Идем по всем строчкам сверху вниз
2) Идем по всем пикселям строчки слева направо
3) Смотрим на смещения у соседей слева и сверху - если они улучшают наше качество - сохраняем их у себя
Таким образом все хорошие идеи которые случайным образом угадались будут распространяться вниз и вправо насколько это возможно.
Чтобы было симметрично и хорошие идеи распространялись так же и вверх и влево - давайте запускать в т.ч. обратный Propagation:
1) Идем по всем строчкам снизу вверх
2) Идем по всем пикселям строчки справа налево
3) Смотрим на смещения у соседей справа и снизу - если их смещение улучшает наше качество - берем лучшее из них себе
Идея 2: как улучшить случайные гипотезы? (Refinement=уточнение)
Изначально еще до Propagation нам надо выбрать хоть какие-то сопоставления - их давайте сделаем случайными.
Но после прохода Propagation когда мы вдохновились решениями соседей и все хорошие сопоставления распространились до куда могут - как генерировать новые идеи?
Можно просто накинуть для каждого пикселя новое случайное сопоставление, и если оно лучше по качеству чем то что у него было до сих пор - заменить.
Но как например заложить в алгоритм идею навроде у нас хорошее сопоставление взятое от соседа, но нам бы его чуть изменить, чуть сместить, чуть уточнить под себя?
Давайте брать не просто случайное сопоставление, а несколько гипотез в экспоненциально убывающих окнах:
- Случайное сопоставление вокруг нашего пикселя в радиусе ширины картинки (по сути - случайная гипотеза во всей картинке)
- Случайное сопоставление вокруг нашего пикселя в половине радиусы ширины картинки (в какой половинке?)
- Случайное сопоставление … в радиусе равном четвертинке ширины картинки (в какой четвертинке?)
- Случайное сопоставление … в окрестности \(\frac{1}{8}\) ширины картинки (вокруг чего?)
- Случайное сопоставление … в окрестности \(\frac{1}{16}\) ширины картинки (вокруг чего?)
- …
- Случайное сопоставление … в окрестности 1 пикселя вокруг нашего текущего сопоставления
Т.е. мы накидываем случайные гипотезы все ближе и ближе к нашей текущей гипотезе:
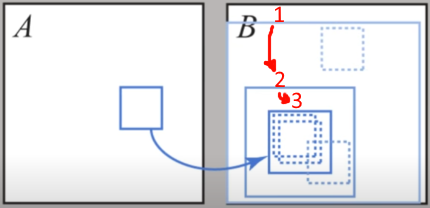
И берем лучшую из них (или оставляем старое сопоставление если оно победило по качеству).
Этот этап называется Refinement = уточнение/улучшение решения.
Идея 3: лучше начать с картинки в меньшем разрешении (Coarse-to-Fine = от грубого к детальному)
В маленькой картинке проще перебрать все гипотезы и в целом окно сопоставления (например 7х7) видит контекст лучше и надежнее.
Так давайте сначала залатаем дырку в низком разрешении и на базе этого залатывания получим неплохой стартовый вариант для следующего разрешения:
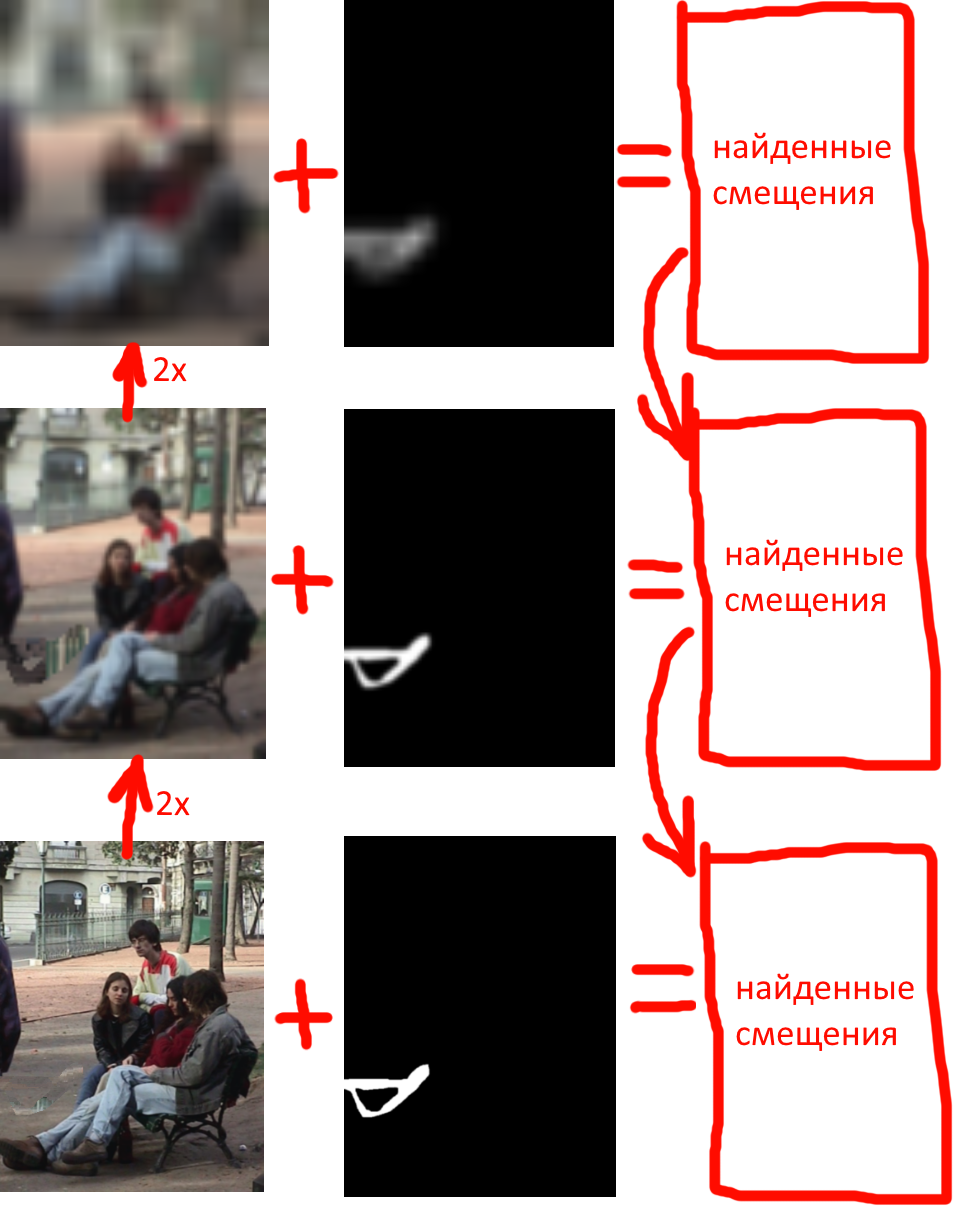
Общая структура кода
1) Взяли картинку, взяли маску.
2) Построили пирамиду из разных разрешений этой картинки (по сути - много раз уменьшаем ее в два раза).
3) Построили пирамиду из разных разрешений этой маски (уменьшаем в два раза).
4) На каждом уровне детализации картинки+маски:
4.1) Если это первый уровень - генерируем случайные сопоставления
4.2) Если это не первый уровень - сопоставления берем с предыдущего уровня
4.3) Выполняем сколько-то итераций, на каждой итерации:
4.3.1) Выполняем Propagation (т.е. распространяем хорошие гипотезы) - вниз и вправо если итерация четная, вверх и влево если итерация нечетная
4.3.2) Выполняем Refinement (т.е. уточнения текущей гипотезы случайными пертурбациями в экспоненциально умешающемся окне поиска)
Технические детали
1) Как построить пирамиду картинок разного разрешения? Пример:
cv::Mat original = ...;
std::cout << "Image resolution: " << original.cols << "x" << original.rows << std::endl;
std::vector<cv::Mat> pyramid; // здесь будем хранить пронумерованные версии картинки разного разрешения
// нулевой уровень - самая грубая, последний уровень - самая детальная
cv::Mat img = original.clone();
const int PYRAMID_MIN_SIZE = 20; // до какой поры уменьшать картинку? давайте уменьшать пока картинка больше 20 пикселей
while (img.rows > PYRAMID_MIN_SIZE && img.cols > PYRAMID_MIN_SIZE) { // или пока больше (2 * размер окна для оценки качества)
pyramid.insert(pyramid.begin(), img); // мы могли бы воспользоваться push_back но мы хотим вставлять картинки в начало вектора
cv::pyrDown(img, img); // эта функция уменьшает картинку в два раза
}
2) Что делать если мы сопоставляем патч \(A\) вокруг пикселя с патчем-донором \(B\) вокруг пикселя на которого указывает сопоставление?
2.1) Если патч-донор \(B\) оказался заползающим на отмаскированную територию, т.е. пытается взять те цвета которые мы пытаемся менять и улучшать - давайте просто выдадим ему очень плохое качество (хуже чем у любого другого сопоставления которое не выходит за пределы картинки, чтобы такое сопоставление всегда проигрывало и никогда не бралось).
2.2) Если патч-донор \(B\) оказался за пределами картинки хотя бы одним пикселем - это плохой донор, он обрезан, его лучше не брать, давайте тоже просто выдадим ему очень плохое качество (хуже чем у любого другого сопоставления которое не выходит за пределы картинки, чтобы такое сопоставление всегда проигрывало и никогда не бралось).
2.3) Если патч \(A\) оказался за пределами картинки хотя бы одним пикселем - это плохая окрестность вокруг пикселя который мы хотим залатать. Что тогда с ним делать? Не бросать же. Так давайте просто не учитывать те пиксели из окрестности, что выходят за пределы картинки. Или давайте вместо их разницы цветов (ведь у них нет цвета) добавлять какую-нибудь константу. От значения этой константы сопоставление-победитель не изменится.
3) Как организовать код так чтобы Propagation стадия была написана без копи-пасты один раз? Чтобы не было варианта про вперед (вниз и вправо) и второго варианта про назад (вверх и влево)? Если нет идей - позовите и обсудим. Вот код подсказка:
bool isForward = true / false;
int iFirst = 0;
int iLast = N; // на самом деле это индекс ПОСЛЕ последнего, в данной иллюстрации у нас в массиве якобы N элементов
int iStep = 1;
if (!isForward) { // если мы хотим протий по массиву в обратном направлении
iFirst = N - 1; // то начинаем с конца
iLast = -1; // заканчиваем как только дошли до элемента сразу за самым первым
iStep = -1; // и шаг теперь не плюс 1, а минус 1, т.к. мы идем назад (уменьшаем индекс)
}
for (int i = iFirst; i != iLast; i += iStep) {
int iPrevious = i - iStep;
int iCurrent = i;
int iNext = i + iStep;
// ...
}
4) Какую метрику для оценки качества сопоставления патча лучше использовать? Можно использовать сумму абсолютных разниц (SAD = Sum of Absolute Differences), но гораздо лучше работает сумма квадратов разниц (SSD = Sum of Squared Differences), т.к. за отклонение цвета штраф обладает квадратичной (более сильной и строгой) зависимостью а не линейной.
5) Как обновить найденные сопоставления при переходе от одного уровня детальности к следующему? Подумайте как обновить каждую стрелочку-сопоставление? Во-первых, каждый пиксель расчетверился, значит каждый из этих новых пикселей хочет вдохновиться старой стрелочкой сопоставлением. Во-вторых, картинка увеличилась вдвое, значит все расстояния увеличились вдвое, значит и стрелочку надо домножить на два.
6) Как ускорить еще сильнее? Заметьте что стрелочки нам нужны не для всех пикселей, но на самом деле и не только для тех что отмаскированы… Подумайте почему? Или закодьте и посмотрите как изменится разница? Это очень интересный вопрос, позовите меня и его будет очень полезно обсудить.
7) Что делать если я не понимаю всю ценность в освоении тайных навыков paint-мастерства? Не хочу изучать Paint.NET и аналоги? Не понимаю что мне все-равно позже надо будет изучить все эти рисования со слоями и прозрачностью для создания презентаций и прочих визуализаций? Тогда вот готовая маска для датасета с клумбой.
{kind=link}
Ссылки
Оригинальная статья представившая этот алгоритм:
Примеры


