Урок 12: Разбиваем картинку на буквы
Задача
Пусть есть такая картинка:

Хочется разделить картинку на много маленьких картинок: одна буква - одна картинка, и тогда дальше можно будет воспользоваться HoG классификатором с прошлого урока:

Документация
На протяжении всего задания предлагается воспользоваться несколькими готовыми функциями из OpenCV, и чтобы с ними было проще разобраться - предлагается использовать документацию.
Вбейте в гугл opencv docs cpp.
Убеждаетесь что сверху слева указана версия библиотеки навроде 4.5.4 (т.к. мы используем версию 4.5.1 или выше - см. файл в корне проекта CMakeLists.txt):
Например представим что мы хотим найти документацию по функции cv::threshold(...):
Теперь с помощью переводчика можно разобраться что делает эта функция:
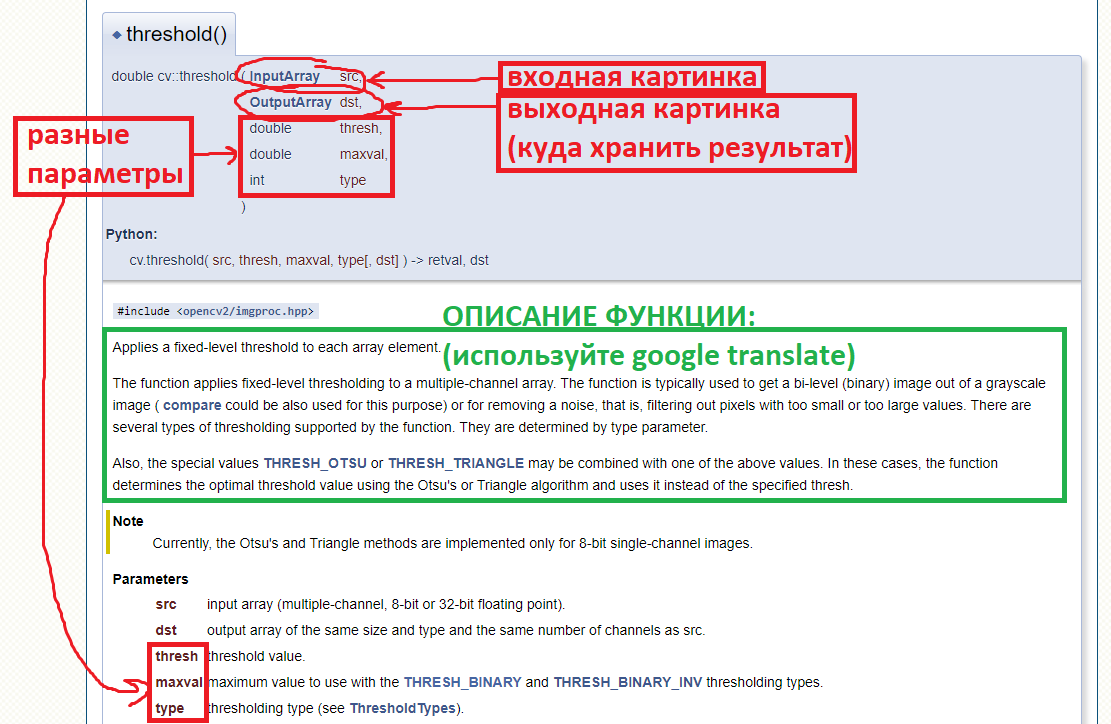
Когда у функции много аргументов (параметров) - легко забыть какой из них вы сейчас хотите указать в среде разработаки (IDE CLion), поэтому удобно поставив каретку внутри вызываемой функции попросить IDE подсказать список названий параметров - для этого нажмите CTRL+P (P - от слова Parameters).
Бинаризация картинки
Давайте сначала сделаем картинку черно-белой.
1) Теперь давайте все почти идеально белые пиксели сделаем окончательно белыми (фон), а почти идеально черные буквы сделаем идеально черными. Это то же самое что и “сравним каждый пиксель с некоторым порогом (например с 127, т.к. полный диапазон яркости от 0 до 255) и все что меньше - занулим, а все что больше - увеличим до 255”:
Этого можно добиться как раз с помощью этой функции cv::threshold(...) (прочитайте про нее документацию):
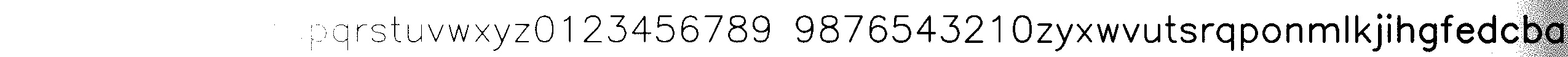
Заметьте что из-за градиента (плавного перепада яркости картинки слева направо) - такой порог выбрать не выйдет:
-
либо мы потеряем буквы слева (т.к. они будут приняты как фон - станут белыми)
-
либо мы потеряем буквы справа (т.к. вместе с ними и фон будет принят за буквы - станет черным и сольется с буквами)
2) Давайте заметим что нам как людям тем не менее очевидно где буквы находятся. И ясно нам это за счет локального контраста. Т.е. порог должен быть не глобальным, а локальным. Буква должна просто быть достаточно сильно отличима от фона.
Как раз с этим может помощь функция cv::adaptiveThreshold(...) (прочитайте про нее документацию):
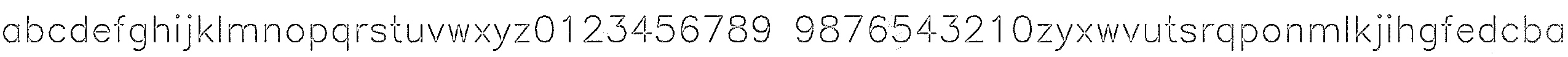
Склеиваем буквы
3) Чтобы буквы не были такими шумными и рваными (иногда даже разваливающимися на кусочки - см. например букву a или цифру 4) - давайте попробуем выполнить морфологические операции - расширение или же сужение, т.е. dilate или же erode.
Прочитайте документацию про:
-
cv::getStructuringElement- по сути это то какие пиксели из окрестности будут учитываться при выполнении морфологического “правда ли что рядом есть хотя бы один белый пиксель?”, иначе говоря нас устроит прямоугольник -
cv::dilate -
cv::erode
Например для cv::erode получаем что-то вроде:
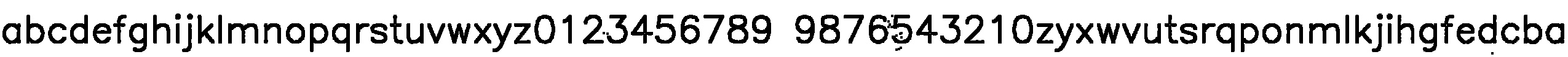
Выглядит неплохо! А какой результат у cv::dilate? А как он меняется при изменении радиуса приложения структурного элемента (т.е. при изменении окрестности по которой мы проверяем правда ли что рядом кто-то есть)?
4) Подумайте какая из этих двух картинок нам дальше больше подходит?
Выделяем компоненты (связанные пиксели)
5) Выделяем контура - очертания букв, для этого подойдет функция cv::findContours (прочитайте документацию!).
Визуализируем результат
6) Чтобы посмотреть как нашлись буквы - давайте нарисуем вокруг каждой из них - прямоугольник (bounding box).
Бонус
100) Если вы со всем справились - возьмите теперь этот подход разбивания на отдельные буквы, затем приклейте к этому результат прошлого урока - распознавание каждой буквы.